Parsing HTML with XPath
XPath is an expression language used to parse and navigate XML-formatted documents such as HTML.
XPath is useful for web scraping and can be used in place of the popular BeautifulSoup Python package.
A key advantage of XPath is its universality. The same selectors will work across browsers and web scraping tools, which smoothes the lines between inspecting live websites, writing code to pull data from HTML pages, and identifying specific web elements to interact with using browser automation tools.
This section will teach you how to write simple, precise, and generalizable XPath expressions to parse and manipulate web pages.
Introduction to XPath
We’re going to identify all the recent article titles and links from NPR. In your browser and go to our example website: https://text.npr.org/
Next, open the dev tools by right-clicking anywhere and selecting “Inspect” (or however else).
Select any element in the “Elements” tab and copy the XPath:
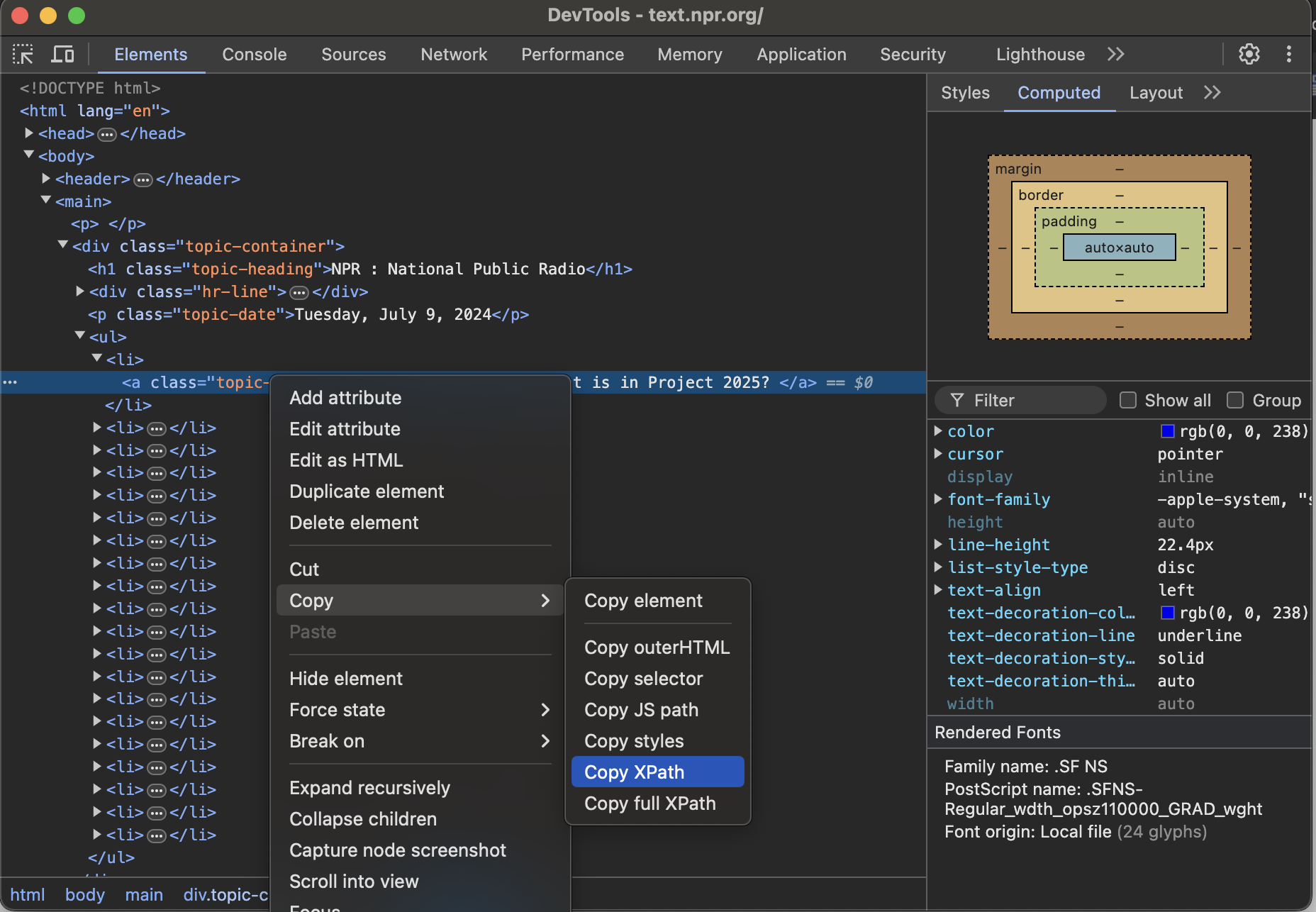
The element we’re selecting is an <a> tag with a link and a title that looks like this:
<a class="topic-title" href="/nx-s1-5035272">What is in Project 2025? </a>The resulting XPath that we copied looks like this:
/html/body/main/div/ul/li[1]/aWhat is XPath?
XPath records hierarchically across a cascade of HTML tags, with the last tag denoting the destination.
It designates where an element lives in an HTML document (as if you were honing in on a street address from the center of the earth).
The example above is long and specific to one element on the page (BAD!). It is called an absolute XPath.
Absolute XPath provides directions to a specifc destination (for example the Shake Shack in Madison Square). However, there’s another form of XPath called a relative XPath that can provide directions to every Shake Shack.
With a little practice XPath can be both precise and generalizable, providing an elegant way to locate and select elements from web pages.
Here is the other extreme: short and generic (ALSO BAD!!).
//aThis relative XPath syntax yields the target element mixed with every other element on the page with an <a> tag. Following the Shake Shack analogy, this XPath represents directions to every restaurant on Earth.
You’ll notice the “//” before the <a> tag, which denotes a search anywhere on the page.
Identifying the optimal XPath in the browser
A key strength of XPath is that you can identify and refine them in browser, and use the same XPath in different frameworks to make web parsing a breeze.
The Goldie Locks approach is not about specifying the exact route (absolute XPath), but rather identifying the destinguishing attributes of the destination (a precise relative XPath).
Let’s jump back to the live NPR website:
In Dev Tools, switch over to the “console” tab. This allows us to execute JavaScript on the page.
We’ll use the
$x()function to select elements on the page by xpath (“x” for xpath). This is unique to devtools and not a standard JavaScript function.
As a start, type a HTML tag such as a “header”, “a”, “div”:
$x('//a')XPath offers an easy way specify attributes and other distinguishable features.
You just add an “@” sign before the attribute name. This allows you to denote specific attribute values //a[@href="/nx-s1-5035272"] or simply the presence of an attribute //a[@href].
Here’s a workflow for honing in to the optimal XPath:
- Start a XPath with a HTML tag with closed brackets:
//a[ ... ] - copy + paste attributes from a live element (for example
<a class="topic-title" href="/nx-s1-5035272">) - Add “@” before each attribute, ending up with:
//a[@class="topic-title" and @href="/nx-s1-5035272"].
From there, you can remove overly-specific attributes. In the case above, the class is unique enough to isolate news articles.
$x('//a[@class="topic-title"]')When available, identify elements using accessibility features (aria) or data attributes. These are less subject to change and are easy to read.
Text Matching
XPath also allows for text-matching.
Here’s how you can match for a link on the page with text mentioning “2025”
$x('//a[@href and contains(text(),"2025")]')To sanity check your results, you can expand the resulting list and click any of the elements. This will highlight the element on the page and shoot you back to the Dev Tools “Elements” tab to view the element.
Web Parsing with XPath
Static HTML
With the correct xpath in hand, we can automate this parsing in Python.
Let’s visit the website and retrieve the static HTML from the page.
import requestsurl = "https://text.npr.org/"
resp = requests.get(url)Compared to BeautifulSoup
If you’re familar with BeautifulSoup, we’re going to be doing the same steps as below. In both cases we’ll search unique patterns between the element tags, classes, data attributes, and other features to isolate the correct elements.
from bs4 import BeautifulSoup
# read the webpage as bs4
soup = BeautifulSoup(resp.text)
# select all the "a" tags with the specified class.
articles = soup.find_all("a", {"class": "topic-title"})
# iterate through each headline and grab the title and link of each story.
data = []
for elm in articles:
link = elm.get('href')
link = f"https://npr.org{link}"
title = elm.text
row = {'link' : link, 'title': title}
data.append(row)
data[:5][{'link': 'https://npr.org/nx-s1-5458512',
'title': 'How good was the forecast? Texas officials and the National Weather Service disagree'},
{'link': 'https://npr.org/nx-s1-5458514',
'title': 'Texas officials race to find survivors after devastating floods '},
{'link': 'https://npr.org/nx-s1-5457278',
'title': 'At least 78 dead and dozens missing after catastrophic Texas flooding '},
{'link': 'https://npr.org/nx-s1-5454890',
'title': '4 things to know about the vaccine ingredient thimerosal'},
{'link': 'https://npr.org/g-s1-75874',
'title': 'Knives, bullets and thieves: the quest for food in Gaza'}]The same example using xpath
Here we’ll read the HTML into lxml to parse elements based on xpath. Note: some frameworks prefer the .// relative syntax (lxml) compared to // (Playwright).
from lxml import etree
# read the webpage as lxml
tree = etree.HTML(resp.text)
# select all the "a" tags with the specified class.
xpath_article = './/a[@class="topic-title"]'
elements = tree.findall(xpath_article)
# iterate through each headline and grab the title and link of each story.
data = []
for elm in elements:
link = elm.get('href')
link = f"https://npr.org{link}"
title = elm.text
row = {'link' : link, 'title': title}
data.append(row)
data[:5][{'link': 'https://npr.org/nx-s1-5458512',
'title': 'How good was the forecast? Texas officials and the National Weather Service disagree'},
{'link': 'https://npr.org/nx-s1-5458514',
'title': 'Texas officials race to find survivors after devastating floods '},
{'link': 'https://npr.org/nx-s1-5457278',
'title': 'At least 78 dead and dozens missing after catastrophic Texas flooding '},
{'link': 'https://npr.org/nx-s1-5454890',
'title': '4 things to know about the vaccine ingredient thimerosal'},
{'link': 'https://npr.org/g-s1-75874',
'title': 'Knives, bullets and thieves: the quest for food in Gaza'}]The outcome is the same between BeautifulSoup and lxml. However BeautifulSoup only works with static HTML you’ve saved or stored in memory.
XPath can be used to parse data in this format, but also can be used to work in browser automation frameworks.
Browser Automation
The same xpath can be used for browser automation frameworks, such as Playwright.
# download software
!pip install playwright
!playwright installRequirement already satisfied: playwright in /Users/leon/miniconda3/lib/python3.7/site-packages (1.35.0)
Requirement already satisfied: pyee==9.0.4 in /Users/leon/miniconda3/lib/python3.7/site-packages (from playwright) (9.0.4)
Requirement already satisfied: typing-extensions in /Users/leon/miniconda3/lib/python3.7/site-packages (from playwright) (3.7.4.3)
Requirement already satisfied: greenlet==2.0.2 in /Users/leon/miniconda3/lib/python3.7/site-packages (from playwright) (2.0.2)from playwright.async_api import async_playwright
playwright = await async_playwright().start()
browser = await playwright.chromium.launch(headless = False)
page = await browser.new_page()The exact function to use XPath is a little different across scraping tools (‘locator’ in the case of Playwright), but the XPath expressions stay the same.
# go to the webpage,
await page.goto(url)
# we use xpath in the `locator` function to select all the articles.
xpath_article = '//a[@class="topic-title"]'
elms = await page.locator(xpath_article).all()
# iterate through each headline and grab the title and link of each story.
data = []
for elm in elms:
title = await elm.text_content()
link = await elm.get_attribute('href')
link = f'https://npr.org{link}'
row = {'link': link, 'title': title,}
data.append(row)
data[:5][{'link': 'https://npr.org/nx-s1-5458512',
'title': 'How good was the forecast? Texas officials and the National Weather Service disagree'},
{'link': 'https://npr.org/nx-s1-5458514',
'title': 'Texas officials race to find survivors after devastating floods '},
{'link': 'https://npr.org/nx-s1-5457278',
'title': 'At least 78 dead and dozens missing after catastrophic Texas flooding '},
{'link': 'https://npr.org/nx-s1-5454890',
'title': '4 things to know about the vaccine ingredient thimerosal'},
{'link': 'https://npr.org/g-s1-75874',
'title': 'Knives, bullets and thieves: the quest for food in Gaza'}]To review, here is how we would find all the article elements across the frameworks we mentioned…
Equivalent functions across frameworks
| Framework | Function | Example |
|---|---|---|
| bs4 | find_all |
soup.find_all("a", {"class": "topic-title"}) |
| Browser console | $x |
$x('//a[@class="topic-title"]') |
| lxml | findall |
tree.findall('//a[@class="topic-title"]') |
| Playwright | locator |
page.locator('//a[@class="topic-title"]').all() |
When things get more complicated
We exhibited XPath’s basic functionality on a simple static HTML page. It really shines when it comes to breaking down a complicated website